SummDiff can generate multiple plausible summaries for the same video, while previous methods can only infer a single deterministic summary.
Video summarization is a task of shortening a video by choosing a subset of frames while preserving its essential moments. Despite the innate subjectivity of the task, previous works have deterministically regressed to an averaged frame score over multiple raters, ignoring the inherent subjectivity of what constitutes a good summary.
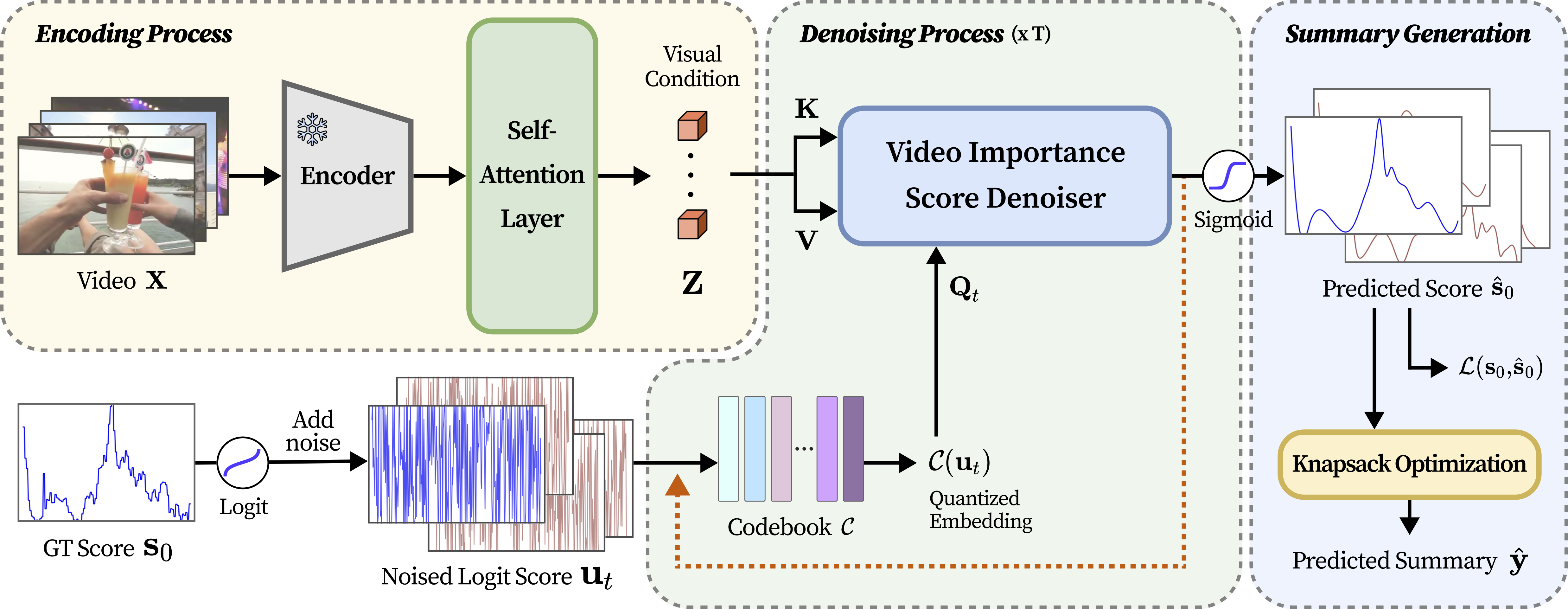
We propose a novel problem formulation by framing video summarization as a conditional generation task, allowing a model to learn the distribution of good summaries and to generate multiple plausible summaries that better reflect varying human perspectives. Adopting diffusion models for the first time in video summarization, our proposed method, SummDiff, dynamically adapts to visual contexts and generates multiple candidate summaries conditioned on the input video.
Extensive experiments demonstrate that SummDiff not only achieves state-of-the-art performance on various benchmarks but also produces summaries that closely align with individual annotator preferences. Moreover, the paper provides deeper insight into the knapsack optimization step and proposes novel metrics for evaluating the optimality of predicted importance scores.
Video summarization is inherently subjective: different people may select different moments while all still producing valid summaries. Most prior methods collapse these diverse annotations into an averaged target score and learn a deterministic predictor. Our method instead formulates video summarization as a conditional generation problem and models the distribution of plausible summaries for a given video.
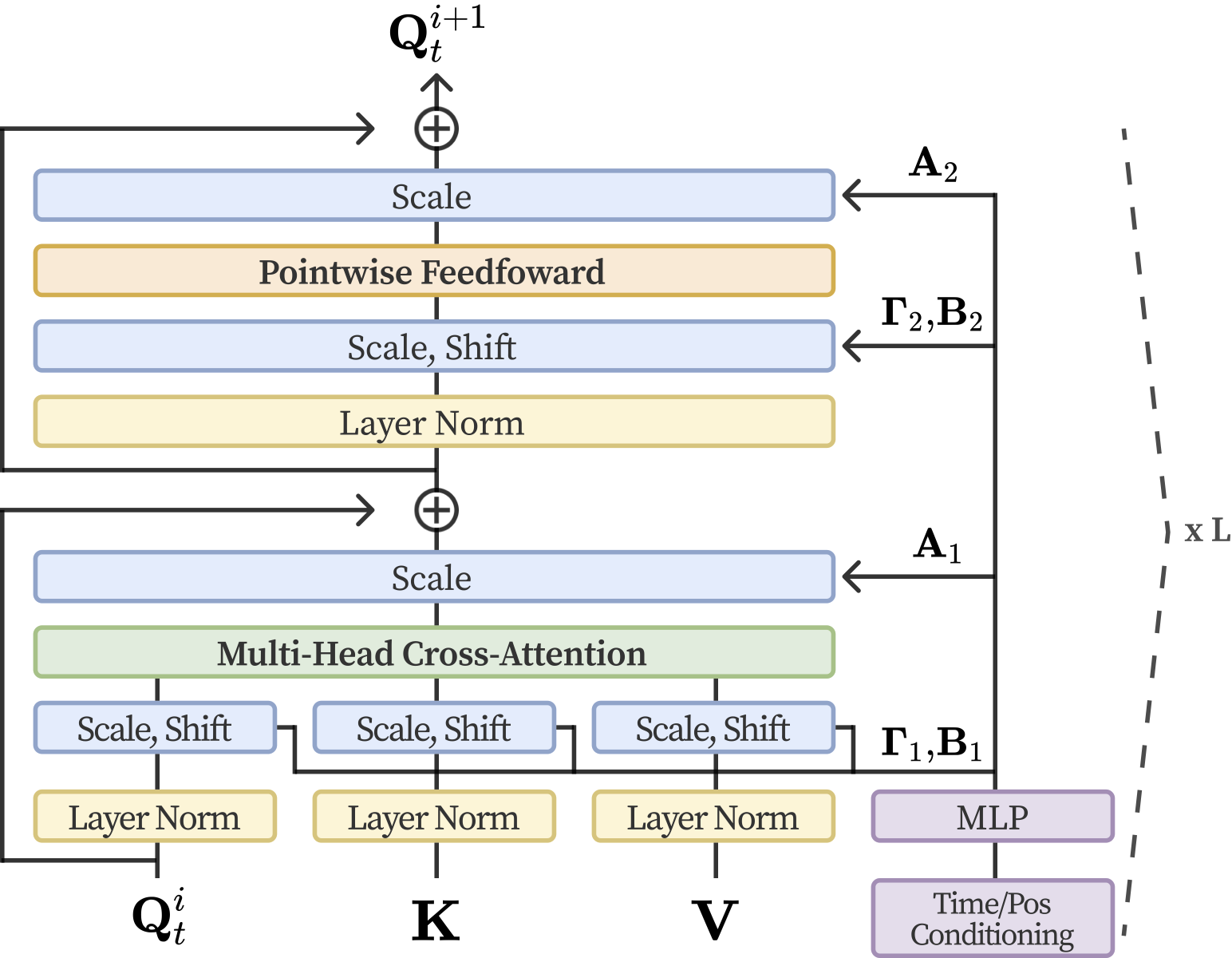
The key idea is to use a diffusion model that denoises importance scores from Guassian noise, conditioned on the input video. This allows the model to generate multiple plausible summaries rather than a single regressed output. SummDiff also introduces new post-processing (knapsack optimization) aware evaluation metrics to better measure whether the predicted importance scores are consistent with the ground truth summary.
@InProceedings{Kim_2025_ICCV,
author = {Kim, Kwanseok and Hahm, Jaehoon and Kim, Sumin and Sul, Jinhwan and Kim, Byunghak and Lee, Joonseok},
title = {SummDiff: Generative Modeling of Video Summarization with Diffusion},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
pages = {15096-15106}
}